検索のしくみに興味があるひとだけ,読んでください.
WASS はつぎの 3 つのサブシステムによって構成されている.
- タグづけサブシステム
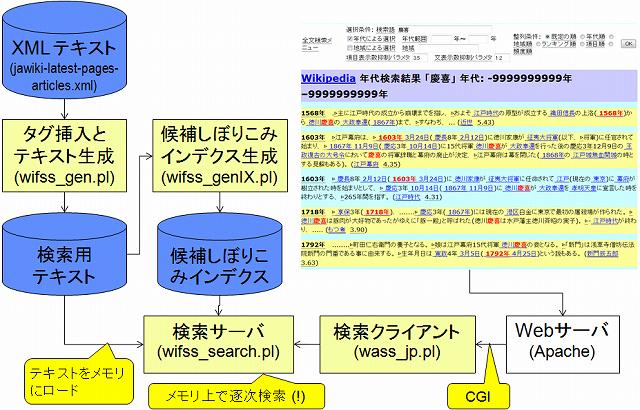
- Wikipedia のテキストを入力し,テキスト中に出現する年代・地名などの情報にタグを挿入した検索用テキストを生成するサブシステムである. タグづけサブシステムの主要部分は wifss_gen.pl という Perl プログラムである. ただし,このプログラムは地名データベースを使用するため,それを生成するためのプログラム (area-list-japan.pl, area-list-world.pl) やそれらの入出力データなども用意している.
- しぼりこみインデクス生成サブシステム
- wifss_genIX.pl というプログラムを使用して,Wikipedia のテキストを入力し,候補をしぼりこんで検索時間を短縮するためのインデクスを生成する. このインデクスをつかうことによって,検索語がふくむすべての文字がその段落にあらわれるかどうかをしらべることができる. あらわれない文字がある段落は候補からはずされる.
- 検索・整列サブシステム
- 検索用テキストをメモリ上に展開し,タグをたよりに指定された検索語,年代,地名などをふくむ段落を検索し,検索結果を整理して表示するシステムである. 検索・整列サブシステムは Web サーバとくみあわせることによって (CGI (Common Gateway Interface) というしくみを使用して) 動作し,検索サーバ・プログラム wifss_server.pl と検索クライアント・プログラム wifss_jp.pl とによって構成されている (下図参照). 検索サーバは Wikipedia がふくむ段落のなかで候補にならないものを,しぼりこみインデクスを使用してみつけだし,候補となるものだけを検索する. また,検索用 GUI (グラフィカル・ユーザ・インタフェース) としては Mozilla Firefox や Internet Explorer のような Web ブラウザを使用する.
候補とされた段落は逐次検索によって検索されるので,このアルゴリズムはもっとも効率的なアルゴリズムだとはいえない. しかし,テキスト全文をメモリにおくことによって,単純なわりには高速に検索することができる.
キーワード: